On a Sunday afternoon about a couple of months ago, when Ye (https://github.com/k-ye) and I were on our way back from a long week of travel, we decided to do something to relax on the train ( to kill time). Since we happened to mention Minecraft and MagicaVoxel, we decided to do a Hackathon, where we use Taichi Lang to create a GPU path tracing voxel renderer. Soon, before we were back home, we had our prototype:
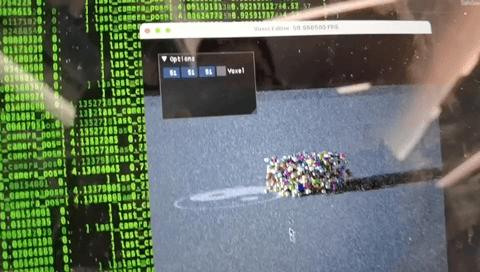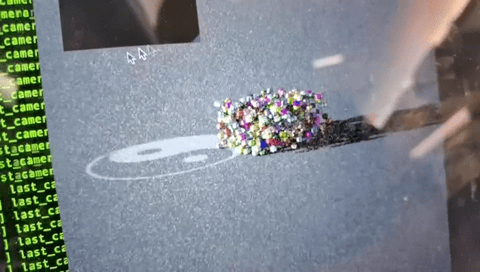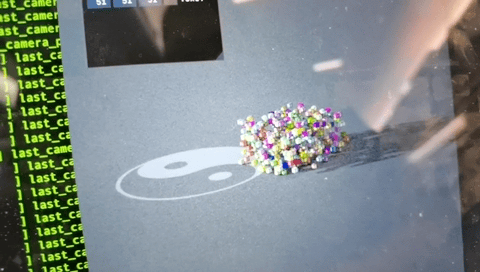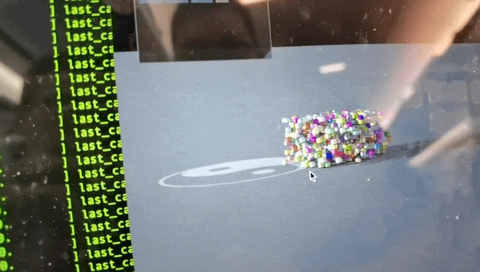
Taichi Lang is embedded in Python and it runs on any operating system and can easily interact with Python. As far as I know, apart from Taichi Lang, there's no such tooling in the Python ecosystem for generating GPU path tracing voxel renders. With Taichi Lang, one can easily create such a renderer (https://github.com/taichi-dev/voxel-challenge/blob/main/renderer.py) in around 300 lines of code.